Tutorial de FreeSurfer n.° 4: Ejecución de recon-all en paralelo
Restricciones de tiempo con Recon-All
Como pronto descubrirá, FreeSurfer tarda mucho en procesar un sujeto individual: entre dieciséis y veinticuatro horas en un iMac típico, con algunas variaciones debido a factores como la calidad de los datos de entrada. Para muchos investigadores, este tiempo de espera puede ser prohibitivo, especialmente si el estudio incluye docenas o cientos de sujetos.
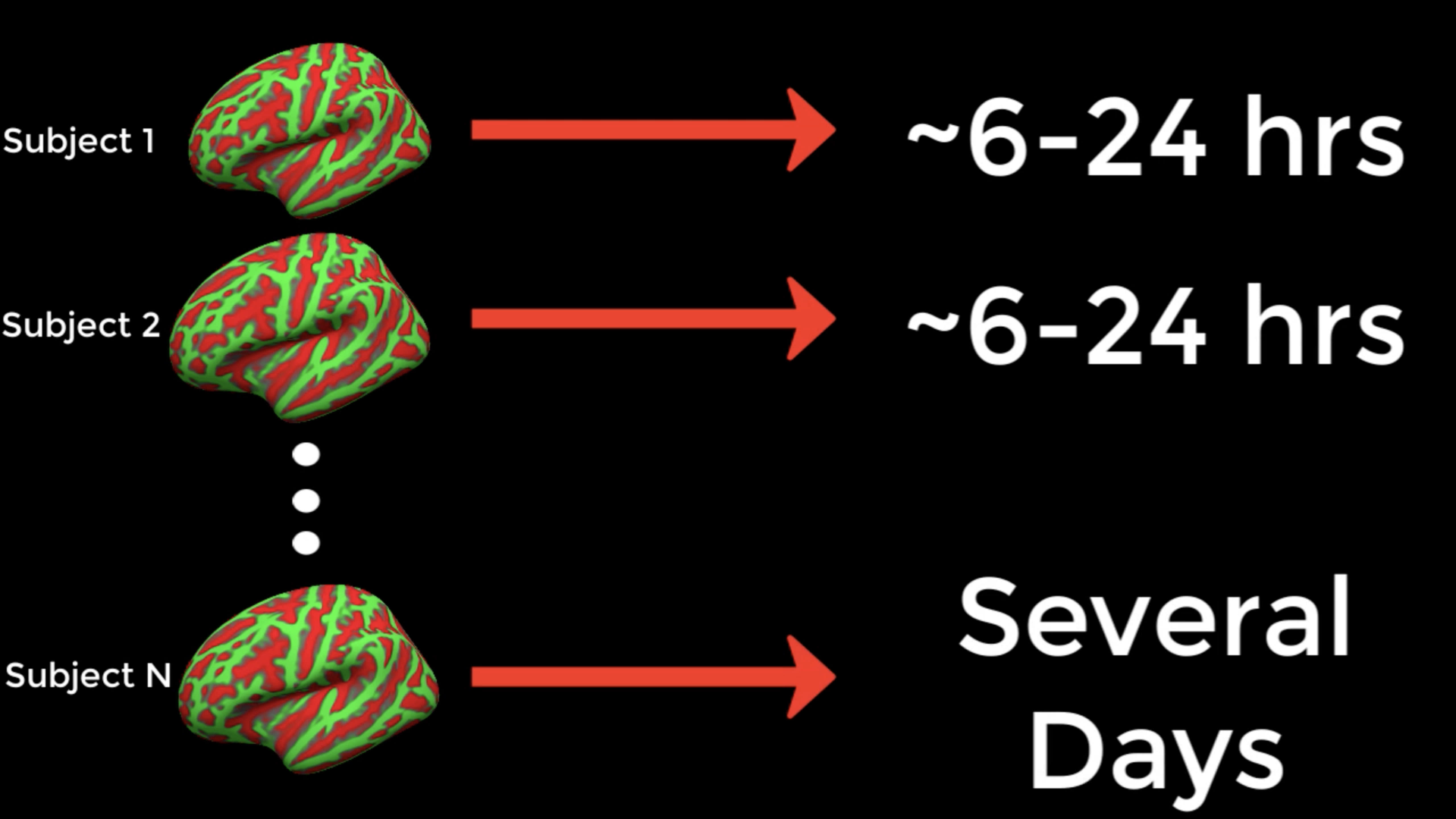
Una forma de reducir el tiempo que lleva analizar tantos sujetos es ejecutar los análisis en paralelo. Las computadoras modernas suelen tener una unidad central de procesamiento con varios núcleos, que pueden usarse individualmente para diferentes tareas. Para ilustrar qué son los núcleos, imaginemos ocho personas y ocho cocinas, cada una con el tamaño justo para que una persona prepare su comida. En esta analogía, cada núcleo de computadora es una cocina. Ocho personas no caben en una cocina, pero si las demás cocinas se desbloquean y se ponen a disposición, cada persona puede preparar su propia comida en cada habitación.
Supongamos que cada comida tarda una hora en prepararse. En lugar de que cada hombre espere su turno en la misma cocina cada hora, todos preparan sus comidas simultáneamente. Lo que de otro modo tomaría ocho horas (es decir, que todos los hombres prepararan su comida en la misma cocina), ahora toma una hora. Si pudiéramos hacer algo similar con nuestro análisis de datos, podríamos terminar de procesar las imágenes anatómicas en un tiempo más razonable.
Descarga del comando paralelo
Volviendo a FreeSurfer, normalmente solo se usa un núcleo cada vez que se ejecuta recon-all. Con el comando parallel, cada instancia de recon-all se puede asignar a un núcleo diferente. Si usa una computadora Macintosh, puede ver el número de núcleos escribiendo lo siguiente:
sysctl hw.cpufísica hw.cpulógica
Lo cual debería devolver algo como esto:
CPU física de hardware: 4
hw.logicalcpu: 8
La primera entrada es el número de núcleos físicos, que es 4; y la segunda entrada es el número de núcleos lógicos, que es 8. Nadie entiende realmente qué significa todo esto, pero todo lo que necesita saber es que el número de núcleos lógicos es el número de trabajos de reconstrucción individuales que puede ejecutar simultáneamente.
El comando paralelo no viene de serie con el sistema operativo Macintosh; deberá descargarlo. Es necesario descargar la aplicación Xcode, disponible en la App Store de Macintosh.
Luego tendrás que ir a `este sitio web``__ e instala Homebrew, un gestor de instalación de paquetes. Homebrew te permite instalar paquetes rápidamente mediante la línea de comandos. Por ejemplo, una vez instalado Homebrew, abre una terminal y escribe lo siguiente:
instalación paralela de brew
Esto instalará el comando paralelo. (Verifique si se instaló correctamente escribiendo parallel -help en la línea de comandos y presionando Enter. Debería ver el manual de ayuda impreso en la ventana de su terminal).
Uso del comando paralelo
Parallel se ejecuta canalizando la salida del comando ls al comando parallel. Por ejemplo, si tiene seis imágenes anatómicas etiquetadas como sub1.nii, sub2.nii … sub6.nii, puede analizarlas en paralelo escribiendo lo siguiente:
ls *.nii | paralelo --jobs 8 recon-all -s {.} -i {} -all -qcache
Analicemos qué hace este comando:
El comando
lsutiliza un comodín para expandir todas las imágenes anatómicas que tienen la extensión.nii.La lista se envía al comando
parallel, que utiliza la opción--jobs 8para indicar que se usarán 8 núcleos para analizar los datos. Cada instancia de recon-all se asignará a un núcleo diferente.El punto entre llaves para la opción
-ssignifica que se debe eliminar la extensión.nii; en otras palabras, la entrada a-sserá sub1, sub2 … sub6.La opción
-iindica utilizar la salida del comandolscomo entrada para el comandoparallel.Las opciones
-ally-qcachetienen el mismo significado que lo discutido en el tutorial anterior sobre recon-all.
Ahora ejecute el comando y observe qué sucede. Si un trabajo típico de recon-all tarda 15 horas en su computadora, vuelva en 15 horas y vea cuántos sujetos se han procesado. Si tiene ocho núcleos y ocho sujetos, debería finalizar en el mismo tiempo que tarda en procesar un sujeto; y si tiene más de ocho sujetos, se procesará uno nuevo en cuanto se libere uno de los núcleos tras finalizar un sujeto.
Análisis del conjunto de datos sobre el cannabis
Si ha configurado el directorio correctamente, todos los temas deberían estar en una carpeta llamada “Cannabis”. Cree otro directorio llamado “FS” y acceda a él. Desde una consola bash (vea la nota anterior), escriba el siguiente código para ejecutar todos estos temas mediante el comando paralelo:
ls .. | grep ^sub- > subjList.txt
para sub en `cat subjList.txt`; hacer
cp ../${sub}/ses-BL/anat/*.gz .
hecho
gunzip *.gz
SUBJECTS_DIR=`pwd`
ls *.nii | paralelo --jobs 8 recon-all -s {.} -i {} -all -qcache
rm *.nii
para sub en `cat subjList.txt`; hacer
mv ${sub}_ses-BL_T1w.nii ${sub}
hecho
El siguiente tutorial le mostrará otra forma de agrupar todos sus procesos de reconocimiento mediante una supercomputadora: Open Science Grid.
Video
Para ver una descripción general en video del comando paralelo, vea este video`__.